The last couple of weeks, part of our Just-BI team explored the possibilities and opportunities of Snowflake. This is an SQL cloud-based data warehouse service. The possibilities of the warehouse for both structured (CSV, tables) and semi-structured data (JSON, XML) sound promising. It requires no administration on the client side, as the user does not need to download a software. All executions are carried out in the cloud. In this blog I will give a brief overview of the architecture of Snowflake, and explore some data loading possibilities.
Architecture
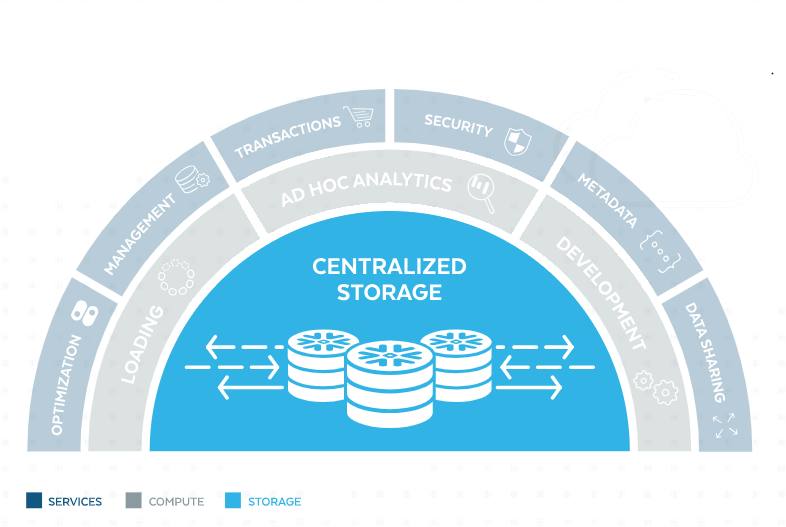
The architecture of snowflake allows for maximum elasticity of storage. Snowflake independently scales compute, storage and services layers.
- The services layer performs the processing of queries. It also provides the security and encryption management. Lastly, it enables the SQL
- The data is processed in the compute layer, performed by virtual warehouses. Note that a virtual warehouse (which Snowflake often refers to as warehouse) is not the same as a data warehouse (DW). Where a DW stores the data, a virtual warehouse is the compute resource in Snowflake. It provides CPU, memory, and temporary storage to perform SQL SELECT statements, and DML operations. Snowflake has the unique feature that multiple virtual warehouses can operate on the same data, without blocking users. Both query results and data are locally cached with computing resources, to improve performance of future queries. The warehouses can be started, stopped, and resized when required (even when running).
- The storage layer holds all query results, tables, and data. Snowflake has designed the storage layer to scale independent of compute resources, making it a scalable cloud BLOB storage. This ensures that running queries are not impacted by data (un)loading. In the storage layer data is split into micro-partitions, which are columnar compressed and encrypted.
Data loading
Let’s take a look at the possibilities with regard to loading data into Snowflake. Apart from the normal SQL statements (SELECT, INSTERT , …) Multiple options exist:
- Bulk loading from a Local File System, Amazon S3, or Microsoft Azure.
- Loading continuously with Snowpipe (this entails immediately loading data from files as soon as they are available in the stage).
- Loading using the Web Interface, the Load Data Wizard.
For this blog, I will examine bulk loading from a local file system and using the web interface to load data. After this I will compare the two methods using an example.
First of all, we will discuss the bulk loading from a local file system. The connection between the local system and Snowflake is made via SnowSQL, where we can execute SQL queries and perform DDL and DML operations.
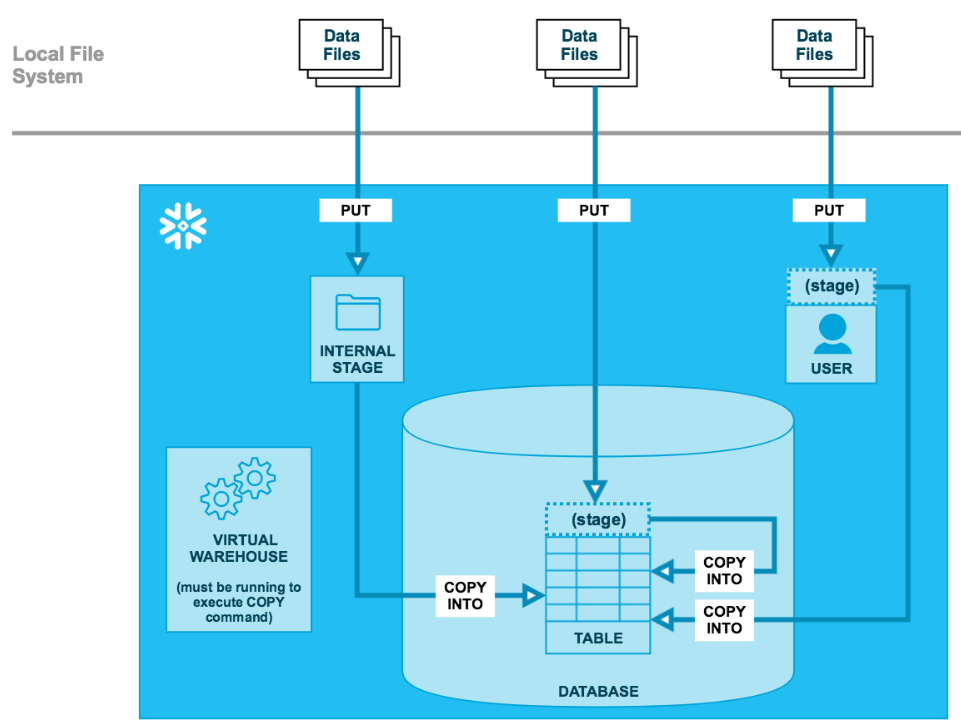
The data can be loaded into Snowflake using the following two steps:
- Use the PUT command to stage one or more files to a Snowflake stage. User stages and table stages are allocated automatically to each user and each table. You can also create named internal stages manually. All of these stages provide different flexibilities with regard to access and privileges.
- Load the contents of the staged files into a Snowflake database table using COPY INTO <table>. This phase requires a running Staged files are internally monitored, by maintaining detailed metadata for each file in the internal stage (e.g. file name, file size, and last modified). Another (limited) option in this phase is to transform the data while loading it into a table, without using temporary tables.
Next, the web interface provides the Load Data Wizard. This wizard combines both the staging and loading phases into a single operation. After the load completes, the staged files are automatically deleted. Although this sounds very useful, note that because this wizard is browser based the number of files that can be loaded is limited. Also each file loaded through the wizard has a restriction on file size of 50MB.
Use case
I tested both methods with a small structured data set (CSV) consisting of less than 1000 rows. The file includes a non-typical date format. Dates are stated as, for example: Wed May 21 00:00:00 EDT 2008. This is not automatically recognized as a date by Snowflake. However, the column in the table we want to load our data into is of type DATE. Let’s investigate how we can transform the date column and load the dataset in our table in the warehouse.
I already mentioned that transforming data is only possible in the second phase of the data loading process. That’s why we can execute the first phase (staging), without any problems, using the following command in SnowSQL:
Put file://C:\Users\XX\Downloads\Sacramentorealestatetransactions.csv @~/staged;
This command uploads the file named Sacramentorealestatetransactions.csv in the Downloads directory on the local machine to the user stage and prefixes the file with the staged folder (@~). This is the folder in the cloud where the file is copied into.

After this, using the TO_DATE function, we are going to adapt the date format. So we can use the standard DATE datatype in our table. Looking at the formats Snowflake can recognize, we can use DY MON DD HH24:MI:SS EDT YYYY. We are going to copy all the columns from to file to our table in the data warehouse, and apply the TO_DATE for column 9 (the column that contains the dates).

We now successfully transformed column 9 into the desired format, and we loaded the data into our table in the data warehouse.
Secondly, I looked at the possibilities to use the web interface to transform and load this file. After choosing what warehouse will be used to load data into the table, and choose the source file from the local machine, the wizard gives us the option to select a file format.
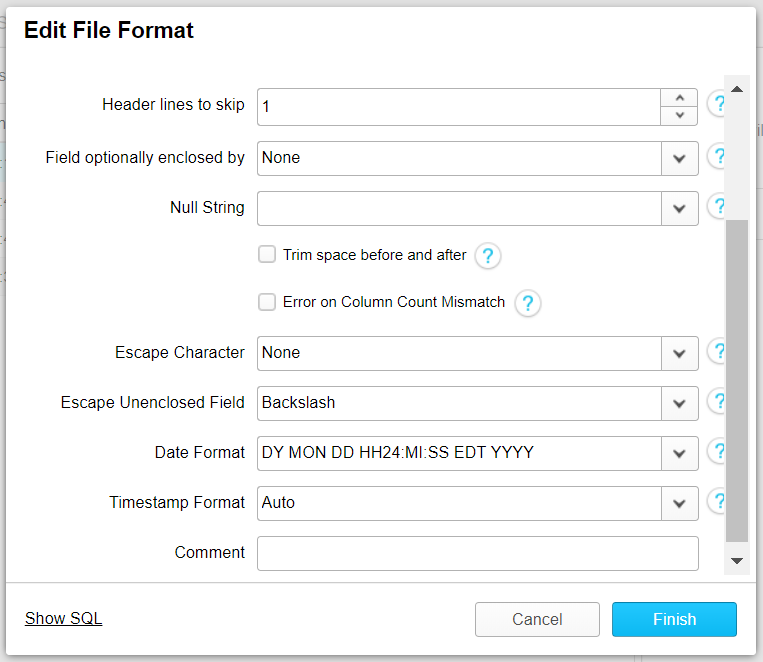
Here we can set how Snowflake should read the file we want to load. The file included the first row as header row, so we set “Header lines to skip” to 1. Most important, we want to set how Snowflake should read the date format. We can insert the format DY MON DD HH24:MI:SS EDT YYYY. This also results in a successful transformation and load into the Snowflake table.
Conclusion
The possibilities and advantages of Snowflake look promising. However, in comparison to for example SAP HANA only a limited amount of data types are possible. Also, Snowflake does not include possibilities to work with hierarchies. I was impressed by how easy it was to understand the tool, and how the scalable architecture provided great performance.
Concluding, Snowflake is an easy-to-use tool, that entails a lot more than has been discussed here. It was nice to explore the different data loading options that Snowflake provides and to experience the tool’s performance.
