1. Introduction
With the dawn of new technologies and maturing of organizations, the quest for big data is being initiated by more corporations every day. In a nutshell, this means (1) combining structured data resulting from a multitude of business operations with more diverse sources holding unstructured data (2) in huge volumes (3) and in higher data refresh velocity. To deal with big data, more and more companies leverage cloud solutions, such as MS Azure. This brings about a variety of hybrid architectures, mixing and matching software from a plethora of vendors.
Ever since SAP plays an essential role in supporting business operations for numerous organizations around the world, data residing in SAP systems should be possible to extract to cloud platforms . However, for a long time the only available Azure Data Factory (ADF) connectors for SAP, as shown in Figure 1, only supported full data loads. For datasets holding millions of records, for sure not an uncommon occurrence, this type of data loading is far from optimal. Preferably, for such big datasets one would like to apply delta loading, where only new or updated records are extracted. With the traditional ADF connectors for SAP, delta loading logic can be applied through a manual and limited workaround. This workaround requires a timestamp or counter column, tracking the most recent or highest value since last extraction. Unfortunately, not all tables contain suitable timestamp or counter columns allowing the delta loading workaround.

Figure 1: Traditional ADF connectors for SAP (https://docs.microsoft.com/ – 19-08-2022)
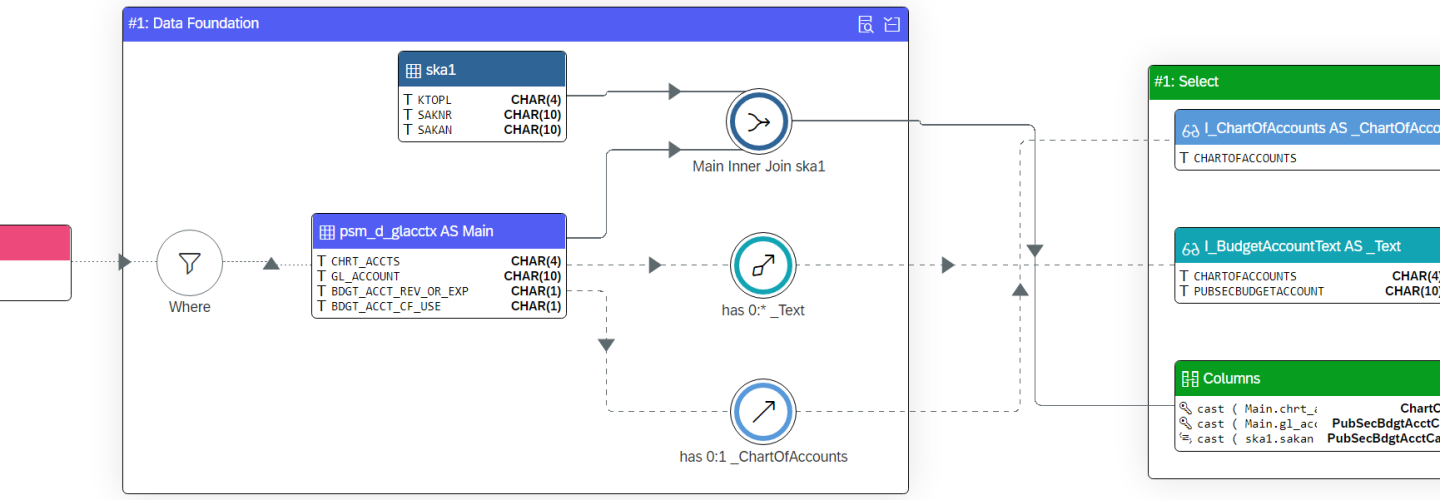
To solve the aforementioned shortcoming regarding data loads, the ADF ODP connector was introduced on June 30th 2022. This connector leverages the SAP Operational Data Provisioning (ODP) framework[1], being able to extract data both in full and delta. See Figure 2 for all underlying SAP objects that can be extracted through the ODP framework.
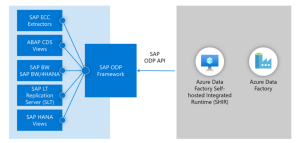
Figure 2: SAP ODP Artefacts for Extraction (https://techcommunity.microsoft.com/ – 19-08-2022)
To illustrate how the extractor works, we have built a short use case as depicted in the next chapter. For (re)building the use case yourself, please take note of the prerequisites in the appendix.
2. Use Case – Data Flow
The use case is based on a 2-step Sales & Distribution (SD) flow. As depicted in figure 3 below, our use case will only exist of a simple process, where (1) a sales order is created, and (2) the order is delivered and goods receipt is booked in a delivery document.
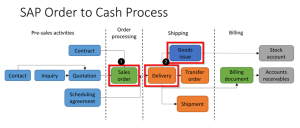
Figure 3: Sales Order Flow (https://sap-certification.info/sd – 19-08-2022)
In below step-by-step guide, we only focused on transactional data flows for sales orders and deliveries. As this was sufficient to test the delta capabilities of the ODP extractor. To go through an entire SD flow, although nice from an esthetic point of view, is unnecessary. Therefore data is not loaded for extractor 2LIS_13_VDITM, since that holds billing documents. Moreover, the same steps can be applied for master data delta loads.
Step 1: Create ADF flow as indicated in the appendix – prerequisites Azure.
Step 2: Load initial data to desired platform, e.g. Azure Data Lake Services (ADLS) or Structured Query Language Database (SQL DB).
- Trigger ADF pipeline created in step 1. This generates the following files:
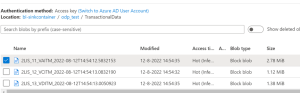
Figure 4: Result Initial Data Extraction in ADLS2
Step 3: Create new sales order scheduled for delivery in S/4HANA (S4) (trx VA01)
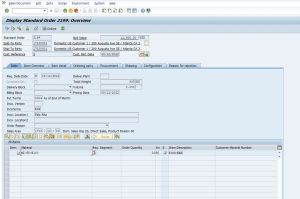
Figure 5: Display of Standard Order Created in S4 (trx VA03)
Step 4: Load updated sales order data to Azure.
- New changes are captured in LIS queue (LBWQ). Run job for LIS application 11 – Sales Documents (LBWE).
- Trigger ADF pipeline created in step 1.
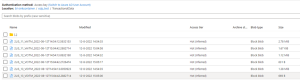
Figure 6: Result Sales Order Data Extraction to ADSL2
Only for sales documents data has been added. The sales order created in step 3.
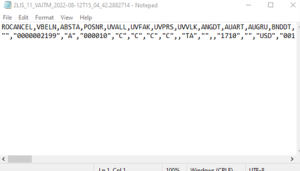
Figure 7: Example of Sales Order Delta Extraction
To illustrate, no extra delivery documents are available. Therefore, a new file is created with header info.
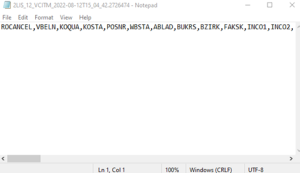
Figure 8: Example of Sales Delivery Delta Extraction
Step 5: Create delivery document for sales order created in step 2 (trx VL01N)
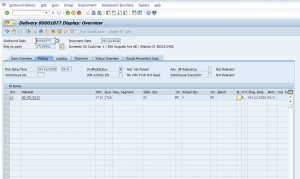
Figure 9: Display of Order Delivery Created in S4 (trx VL03N)
Step 6: Load updated delivery data to platform from step 1.
- New changes are captured in LIS queue (LBWQ). Run job for LIS application 12 – Delivery Documents (LBWE).
- Trigger ADF pipeline created in step 1.
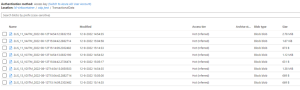
Figure 10: Result Order Delivery Data Extraction to ADSL2
Only for delivery documents data has been added in ADLS2. The delivery document created in step 5.
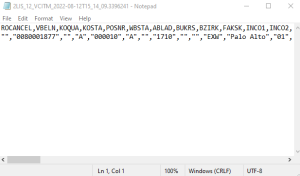
Figure 11: Example of Sales Delivery 2nd Delta Extraction
3. Conclusion
In conclusion, we can state that the SAP ODP connector works as expected and is very user-friendly. As a next step, we will investigate the possibility of dynamic creation of sources and targets, and their related mapping. Also known as metadata driven processing, inspired by an excellent blog[2] regarding best practices for implementing ADF. Naturally, we will integrate the dynamic capabilities in our current SAP ODP connector use case.
4. Appendix – Prerequisites
The prerequisites described below are purely focused on SAP customizations and Azure build required for our use case. Our assumption is that the technical setup of both SAP and Azure environments have been completed already. If not, see Microsoft documentation for the required technical setup steps[3].
- SAP
Activate required LIS extractors (trx LBWE) and fill setup tables (trx OLI7BW/OLI8BW) in S4.
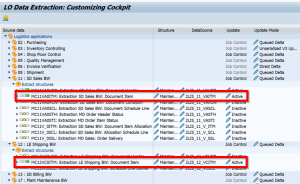
Figure 12: S4 Logistics Cockpit Configuration
- Azure
Create linked service to your S4 system, applying settings as in figure 13:
- Choose logical linked service name
- Choose integration runtime related to your S4 system
- Enter connection details for your S4 system
- Connect with a technical user, we created dedicated user ADFREMOTE in S4
- Choose logical subscriber name, to clearly differentiate between different subscribers in SAP’s ODQ monitor (trx ODQMON)
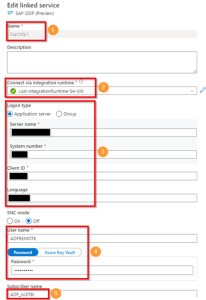
Figure 13: Settings for Linked Service
Create datasets per source and target dataset representing source table in SAP and target in Azure. Creation of 2LIS_13_VDITM datasets is not necessary for current use case.

Figure 14: Source Datasets in ADF
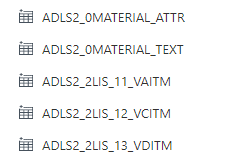
Figure 15: Target Datasets in ADF
Create ADF pipeline with “copy data steps” per table to be extracted. Creation of 2LIS_13_VDITM copy data step is not necessary for current use case.
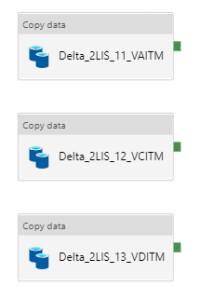
Figure 16: Copy Data Steps for SD Flow
Example Delta_2LIS_11_VAITM, copy step source settings.
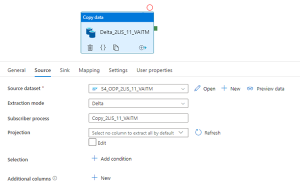
Figure 17: Copy Data – Source Settings
Example Delta_2LIS_11_VAITM, source dataset settings.
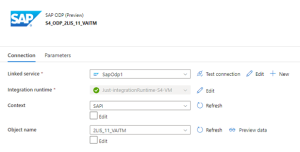
Figure 18: Dataset – Source Settings
Example Delta_2LIS_11_VAITM, copy step sink settings.
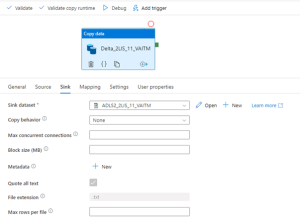
Figure 19: Copy Data – Sink Settings
Example Delta_2LIS_11_VAITM, sink dataset settings.
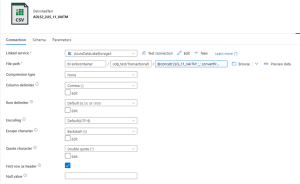
Figure 20: Dataset – Sink Settings
In file path, we concatenate the extractor ID + timestamp of extraction in the file name.
@concat(‘2LIS_11_VAITM’,’_’,convertFromUtc(utcnow(), ‘W. Europe Standard Time’))
[1] For more information regarding SAP ODP framework, see following blog by Rajat Agrawal: https://blogs.sap.com/2020/10/02/anatomy-of-the-operational-delta-queues-in-sap-odp-extractors/
[2] Best Practices for Implementing Azure Data Factory, by Mr. Paul Andrew: https://mrpaulandrew.com/2019/12/18/best-practices-for-implementing-azure-data-factory/
[3] Microsoft documentation on technical setup requirements for SAP and Azure environments: https://docs.microsoft.com/en-gb/azure/data-factory/sap-change-data-capture-prerequisites-configuration
Audience: Azure Data Engineers, SAP BW Consultants, SAP BW Architects, Data Integration Specialists
Authors: Arjen Koot, Mitchell Beekink